Exploratory factor analysis of the Big Five Inventory: Walkthrough with the psych pagackage
R
exploratory factor analysis
Author
Affiliation
Deon de Bruin
Department of Industrial Psychology, Stellenbosch University
Published
January 21, 2025
Exploratory factor analysis
Exploratory factor analysis (EFA) is a statistical technique that researchers use to find the latent structure underlying a set of manifest variables. In the context of scale development and validation EFA is typically used to (a) identify the number of factors (latent variables) that underlie a set of scale items, and (b) identify the items that are the best and worst indicators of the factors. With respect to the latter, the best items are typically those that have a salient relationship with one and only one factor. The worst items may come in two varieties. First, they are items that do not have a salient relationship with any of the factors, or second, they are have salient relationships with two or more factors.
For instance, we might expect (a) that an EFA of the Big Five inventory will show that five major factors underlie the 25 items, and (b) that each of the say, Extroversion items, have a salient relationship with one and only one factor (and the same applies for the Neuroticism, Conscientiousness, Agreeableness, and Openness items). A result that corresponds with this structure will give us confidence that the items are actually measuring the constructs they are intended to measure. By contrast, a result that produces more than five major factors or one that shows that some items fail to have a salient relationship with any of the factors, or one that shows that items have salient relationships with the “wrong” factors, will indicate that the items are not operating as expected.
How is this different from confirmatory factor analysis?
A confirmatory factor analysis (CFA) of the Big Five Inventory would start with an explicit measurement model where the number of factors are fixed at five and where each item is allowed to have a direct relationship with one and only one factor. For instance, all the Extroversion items will be specified to have a direct relationship with the Extroversion factor, but no direct relationships with the remaining factors, and so on. Here the task of the factor analysis is typically to (a) examine how well this pre-defined structure (or measurement model) fits observed data, (b) to estimate the strength of the relations between the items and the factors, and (c) to estimate the strength of the relations between the factors. Good fit will give us confidence that the items are functioning as expected, whereas poor fit will indicate that the measurement model may need to be revised.
By contrast, an EFA is less restrictive (it is also sometimes referred to as unrestricted factor analysis). First, rather than forcing a predetermined number of factors on the data, the analyst will allow the data itself to suggest the number of factors to “extract” or retain. Second, in an EFA all items are typically allowed to have relationships with all the factors. Again, the analyst will allow the data to reveal which items have strong relationships with which factors.
In practice, an EFA is seldom done in a pure exploratory fashion. In most case it is likely that the analyst will have ideas of (a) how many factors to expect and (b) which items are likely to have strong relationships with which factors. This is so because psychological tests and scales are typically developed to reflect a theoretical structure, where the developers know what latent variables they want to measure and the items are explicitly written to reflect those latent variables.
Exploratory factor analysis and the development of the Big Five model of personality
The development of the Big Five model of personality actually is a very good example of how exploratory factor analysis was used in a true exploratory fashion to discover (without a pre-determined theory or model) what the basic dimensions of personality are. This line of research is based on the so-called “lexical hypothesis”, which holds that if a personality attribute is important, there will be a word in the lexicon to describe it. Much of this work focused on adjectives, such as “friendly”, “aggressive”, “scatter-minded”, “lazy”, “nervous”, “humorous”, “ambitious”, and so on.
Across many different languages, countries and cultures researchers have discovered (using the technique of EFA) that ratings of people’s personality attributes (as reflected by such adjectives as listed above) typically yielded five major latent variables (or factors).
In practice, these types of studies identify large numbers of adjectives that would be representative of the lexicon of personality descriptors. Next, the researcher(s) ask large numbers of people to rate themselves (or sometimes other people) on each of the adjectives. These ratings typically focus on how well the adjective describes the person and could, for instance, be done using an ordinal rating format (e.g. 1 = Not like me at all, 2 = A bit like me, 3 = Like me, and 4 = Very much like me), or a binary format (1= No and 2 = Yes). EFA is then performed on these ratings and the goal is to allow the data to reveal (a) the number of latent variables or factors that underlie these adjectives, and (b) the nature or meaning of the factors. The latter is accomplished by inspecting the particular adjectives that have strong relationships with the various factors. In this way, EFA was used to “discover” (without restrictions) that across languages, countries and cultures, the lexicon describing personality attributes can be reduced to five major factors, and that these factors could be labeled as Extroversion, Neuroticism or Stability, Agreeableness, Conscientiousness, and Openness or Intellect.
Many different personality inventories and scales of the Big Five factors have been developed on the basis of this corpus of exploratory factor analyses . The Big Five Inventory is one such scale. Note that the scale was explicitly developed to measure the Big Five factors and that the items were carefully selected to serve as indicators of these factors. An EFA of the Big Five Inventory takes place against the background of this knowledge. Whereas the EFA will be done without (too many) restrictions, the analysis is not entirely exploratory.
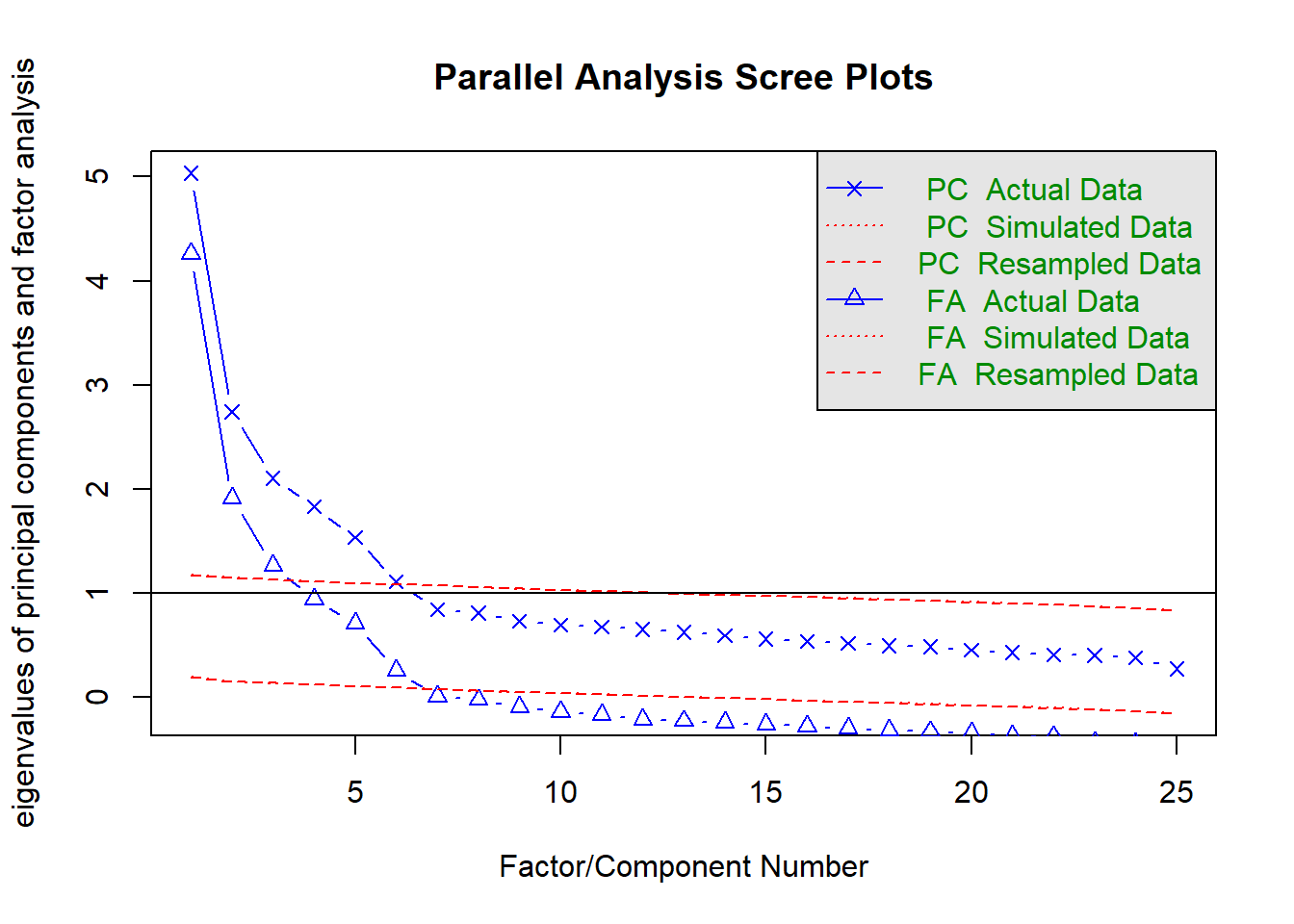
Third, we examine the scree and parallel analysis plot to help determine the number of factors. The scree-plot shows an elbow in the line that connects the eigenvalues of the factors at the seventh factor, which suggests that six factors should be retained. Parallel analysis also suggests that six factors should be extracted. This is somewhat surprising, given that the BFI is supposed to measure five personality factors.
fa.parallel(mydata)
Parallel analysis suggests that the number of factors = 6 and the number of components = 6
#bfi.keys#paSelect(bfi.keys, mydata, plot = TRUE)
Performing the EFA (round 1 with six factors)
Fourth, we perform the first exploratory factor analysis. We extract and rotate six factors. The factor loadings and factor correlations were estimated with the default “minres” (aka “unweighted least squares”) estimator. The factors were rotated to the default “direct oblimin” criterion.
Inspection of the rotated factor pattern matrix shows five well-defined factors that each have at least five salient factor loadings, and one poorly defined factor with three salient (but relatively low factor loadings that range from 0.30 to 0.41). The pattern of salient factor loadings (i.e. loadings > 0.30) indicate that the the first factor corresponds with Neuroticism, the second with Extroversion, the third with Conscientiousness, the fourth with Agreeableness, and the fifth with Openness. The psychological meaning of the sixth factor, which is loaded by one Conscientiousness item and two Openness items, is not clear.
## Plot the item complexitieslabels <-names(my_efa2$complexity)item.complexity <-data.frame(labels, my_efa2$complexity)colnames(item.complexity) <-c("Item", "Complexity")ggplot(item.complexity, aes(x =reorder(Item, Complexity), y = Complexity)) +geom_point() +labs(x ="Items", y ="Complexity", title ="Complexity of the BFI items") +theme(axis.text.x =element_text(angle =90, hjust =1))
Examining the replicability of the factors
We can also examine the internal replicability of the five and six-factor solutions. Factors that do not replicate across different samples of persons from the same population are of less scientific interest than factors that do replicate across different samples.
Ideally, the replication process should be repeated several times. With each round the random samples will be different. If a consistent pattern emerges across the different rounds of analyses greater confidence can be placed in the results.
Randomly split the data into two data frames
ncases <-nrow(mydata)prop1 <-0.6prop2 <-1- prop1 tf <-as.vector(c(rep(TRUE, prop1*ncases),rep(FALSE, prop2*ncases))) tf.random <-sample(tf) # Randomly shuffle TRUE and FALSE data1 <- mydata[tf.random, ] # Select the rows corresponding with TRUEdata2 <- mydata[!tf.random, ] # Select the rows that don't correspond with TRUE (i.e. FALSE)library(psych)nrow(data1)
[1] 1680
Perform the factor analysis on sample 1
my_efa_s1 <-fa(data1, nfactors =6)
Perform the factor analysis on sample 2
The factor pattern matrix of sample 2 is rotated to a target defined by the rotated factor pattern matrix of sample 1. This will ensure that the factors of sample 2 are as similar as possible to those of sample 1.